
Imagine a world where your complex problems are solved with finesse and affordability.
When lives are on the line, downtime is not an option. That was the challenge brought to us by a real-time language translation company serving hospital networks and 911 operators across the U.S. Their translation platform acts as a critical bridge between first responders and non-English speaking patients, where even a few seconds of inaudible calls could impact patient care — or worse, cost lives.
Their existing applications were already optimized for uninterrupted operation, but they needed a data network design to match. Our mission? Build a rock-solid network that upholds their 100% uptime goal while addressing potential points of failure across the OSI model.
Here’s how we made it happen.
The Pragmatic Truth About 100% Uptime
Many believe 100% uptime is a magical standard that few can achieve. The reality? It requires meticulous attention to every layer of the OSI model—from physical infrastructure to application-level redundancy. Even tech giants like Google and Microsoft experience outages, but their systems are designed to fail over seamlessly, so end users rarely, if ever, notice.
To achieve true resilience, a network must be prepared to overcome a plethora of challenges:
- Physical Layer Failures: Fiber cuts, power outages, or hardware malfunctions.
- Application Layer Issues: Software bugs, memory leaks, or third-party integration failures.
- Human Error: Because mistakes happen—even to the best of us.
By designing for resilience at every layer, we can minimize disruptions and meet the uncompromising demands of industries that have no room for downtime.
Our Solution Architecture
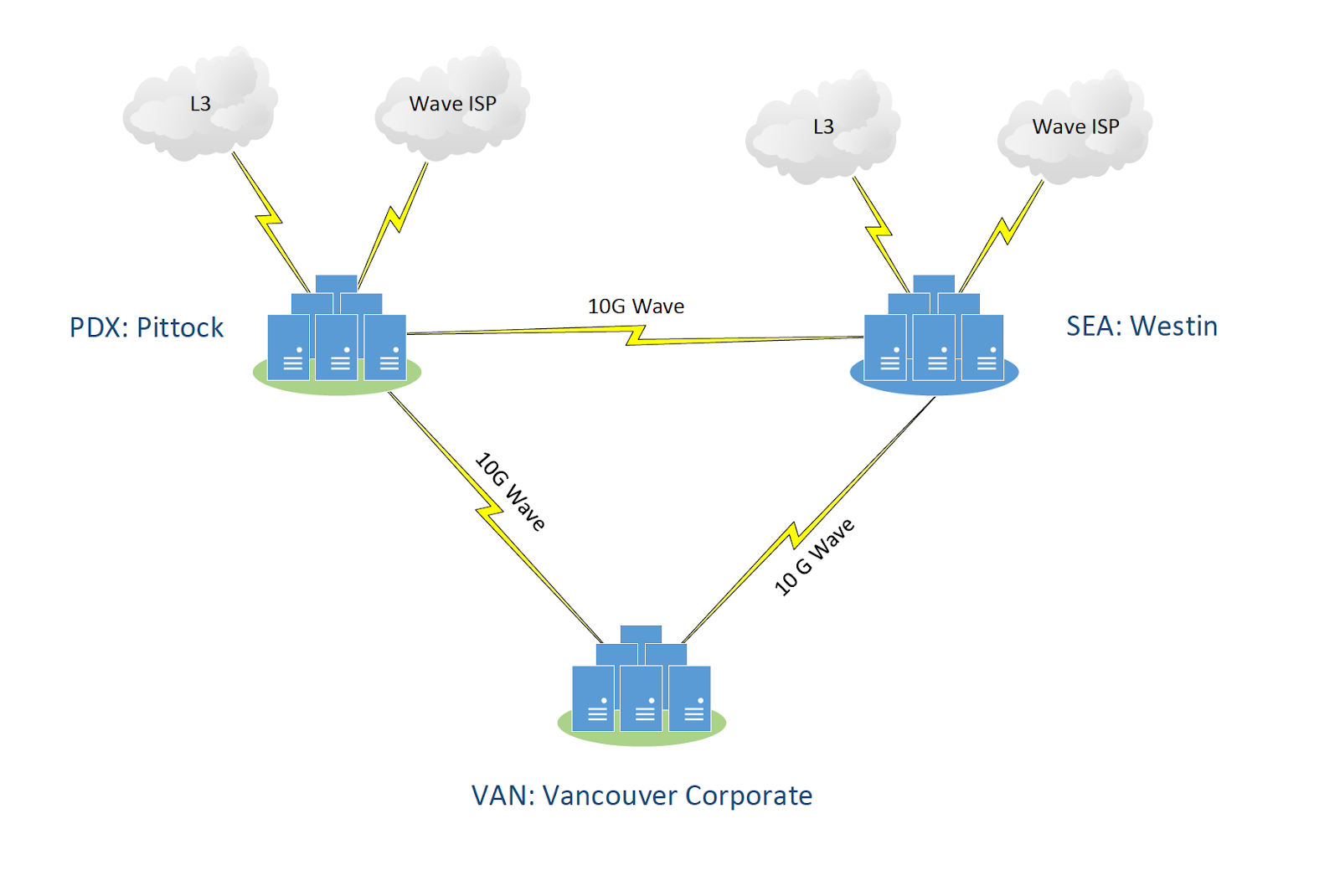
At the Physical Layer, we built a 10Gbps triangular backbone connecting three critical locations: two Carrier Hotel data centers in major cities and the company’s corporate headquarters. To ensure true physical diversity and redundancy, we provisioned diversely routed optical WAVE circuits, which we verified through KMZ files—geospatial maps that show the exact fiber routes between data centers. This allowed us to eliminate single points of failure at the fiber level. We also provisioned a new public Autonomous System Number (ASN) and a /23 block of public IP space to give the customer full control over their routing.
At each data center, we installed dual Tier-1 ISPs with direct connections to local Internet Exchange Points (IXPs). Inside each facility, we built highly available network zones, including redundant Cisco switch stacks, Cisco Firepower firewalls, and Cisco ASR routers to terminate ISP circuits and ensure no single device or connection could take the network offline.
The Data-Link and Network Layers
While redundancy is critical, the real challenge lies in how fast the network can detect a failure and automatically reroute traffic — without users noticing.
To achieve this, we implemented Border Gateway Protocol (BGP) for global Internet routing, combined with Cisco’s Bi-Directional Forwarding Detection (BFD).
BFD acts like a real-time "health check" for the network, detecting fiber cuts or hardware failures in milliseconds. The moment an issue is detected, BGP automatically reroutes traffic to the alternate data center — in less than a second.
We also split the customer’s public IP address block (/23) between both data centers, ensuring Internet traffic naturally flows to the primary location, while the backup data center is always on standby, ready to take over if a failure occurs.
For internal routing, we used Open Shortest Path First (OSPF), integrated with BFD for faster convergence within the private network. By tuning OSPF’s failover settings, we achieved internal failover times as low as 50ms, ensuring real-time translation traffic remains uninterrupted, even during hardware maintenance or software upgrades.
The Software-Based Failover Strategy
While we focused on building resilience at the network layer, the customer’s development team had already designed their core translation platform to be portable between data centers.
This meant that during planned maintenance or unexpected failures, their entire application stack could be instantly moved to the secondary data center, without end-users ever experiencing downtime.
The Result?
In the world of emergency response and healthcare communications, this level of reliability isn’t just extraordinary — it’s life-saving. With this design, the customer’s real-time translation services can now operate with complete confidence, even during network failures, ISP outages, or scheduled maintenance windows. By building redundancy into every layer of the network — from fiber paths, to Internet routing, to application portability — we were able to deliver a rock-solid infrastructure capable of supporting mission-critical services, 24/7.
Now, that’s what we call designing for mission-critical uptime. Wouldn’t you agree?
